I am creating a form that will be completed multiple times for the same project, and would like to set form fields to advance automatically, based on previous entries, when the form is submitted.
E.G. for fields: Org, Team, and 4 Member IDs:
Org: 1 Team: A ID1: 1 ID2: 2 ID3: 3 ID4: 4 – user submits to list (repeater), and form fields change to:
Org: 2 Team: B ID1: 5 ID2: 6 ID3: 7 ID4: 8
I have gotten everything to work except for advancing to the next letter. I’m sure there’s a simple fix but I sure don’t know what it is…
I managed to work out two methods to “advance” or increment an alphabetical character, or in other words, get the “next letter in the alphabet.” One uses javascript injection (not officially supported by Axure) and the other uses “pure Axure”.
Axure has some handy built-in javascript string functions, but not all javascript string functions and methods are supported.
For your needs, there is .charCodeAt(index) which returns a numeric code (UTF-16) for a character. For instance, ‘a’ has UTF-16 code = 97, ‘b’ = 98 and so forth. So, you could theoretically get the code for a letter, add 1, then convert that back to a character to get “the next letter.” In javascript, this is done with String.fromCharCode() …However, this string function/method is not supported in Axure (not sure why not) so this approach pretty much leaves you hanging (unless there is some cute trick I don’t know to convert a code to a character in Axure.) Thus, as far as I know there is no “simple fix” for you here.
My first attempt was to just get the “standard javascript” method to work. The simplest and most reliable way I’ve found for this in Axure in general is to first set a global variable value via javascript and then use standard Axure actions to apply that variable value, rather than try to set the text value of a widget directly via javascript–especially for Text Field widgets and especially especially for widgets in repeaters.
My “secret sauce” is this javascript injection:
Open Link
javascript:$axure.setGlobalVariable(“OnLoadVariable”, String.fromCharCode([[LVAR1.charCodeAt(0)+1]]));`
Where LVAR1 is a local variable pointing to your widget with some text on it–your “input” widget.
This takes the first character of the text value (via .charcodeAt(0) ). So if the widget has “A” or “Albert” it works the same, taking only “A”.
You could replace LVAR1 with the name of a global variable if you want.
Where OnLoadVariable is the default built-in global variable in Axure.
You could insert the name of any global variable you’ve set up.
Note that it is best/necessary to wait at least 50 ms between javascript calls and between using javascript and Axure events/actions which depend on javascript. So, I have a Wait 50 ms action between this javascript call and the next action to Set Text using the resulting value of OnLoadVariable.
So, that’s the closest I could get to a “simple fix” but it’s not that simple and while it works, it is a hack and not officially supported, so use at your own risk.
Now, Axure also does not support string arrays which would be an “old school” method for this problem. But, it can be faked pretty well in this simple case. Here’s the approach:
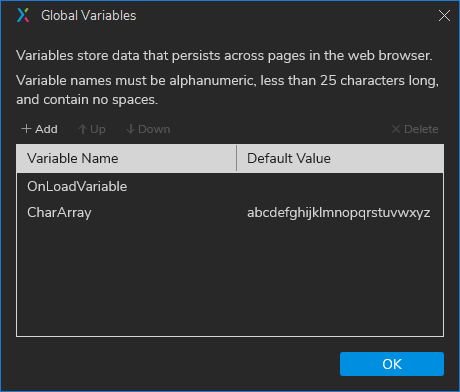
Create a global variable with the alphabet as its default value (or set it via Loaded or Page Loaded events). I added this to my demo file to make a default string value for a new global variable named CharArray:
Then use some Axure string functions to get the next character in the alphabet string:
Find the position (index) of your input character (e.g., ‘a’) in CharArray with the .indexOf() function in this Axure expression: [[CharArray.indexOf('a')]] --this would return 0 (zero) as ‘a’ is the first character and the index starts at 0. So ‘b’ would have an index of 1 and ‘z’ would be 25.
Extract the next character from the string with the .substr() function: [[CharArray.substr(N+1, 1)]] (where N is the index of your input char.)
You can “chain” these functions together in one elegant line of Axure code (again, where LVAR1 points to your input widget or character):
Set Text
myWidget to “[[CharArray.substr(CharArray.indexOf(LVAR1)+1, 1)]]”
So, that’s my “pure uncut Axure secret sauce” solution. I improved it a bit by handling lowercase and uppercase letters (inspect the Interaction code for the “Next Letter” button) and error handling for “non letters”.
You could also include digits in the default value for CharArray, which seems silly, but would give you one consistent way to handle alphanumeric “advancing” --so ‘1’ would convert to ‘2’ in same way that ‘A’ would convert to ‘B’. Make sense?

 line of Axure code (again, where LVAR1 points to your input widget or character):
line of Axure code (again, where LVAR1 points to your input widget or character):